
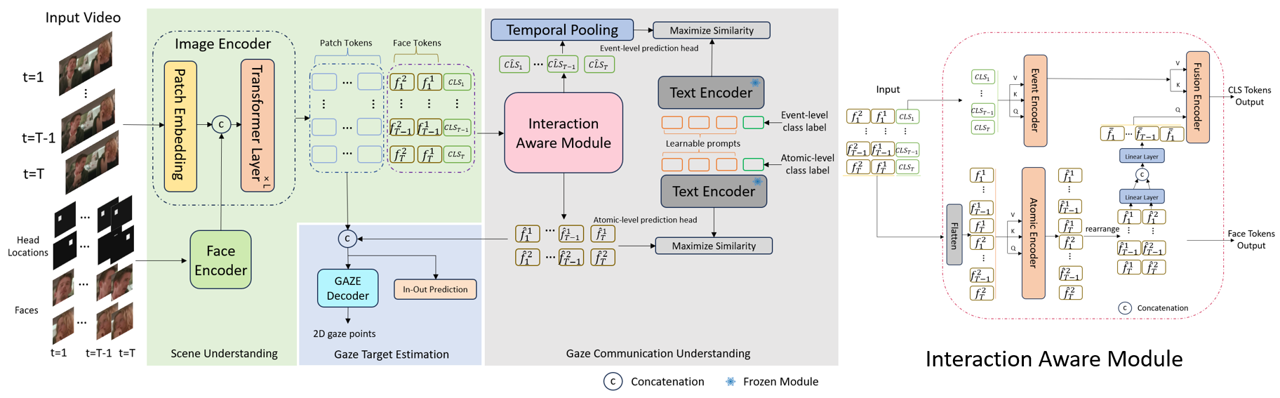
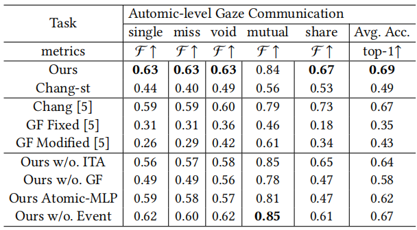
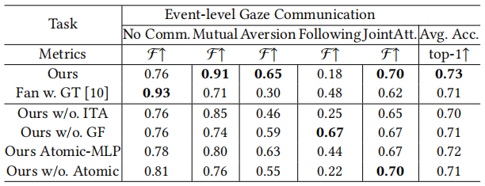
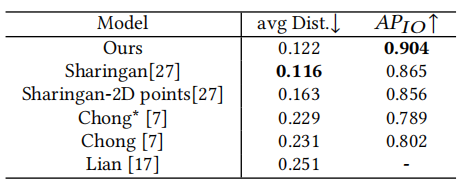
Human gaze communication is complex, comprising atomic-level (e.g. mutual, share, etc.) and event-level (e.g. follow, aversion, etc.) behaviours. Various methods have been developed to analyse gaze communication in images, but they typically fall short of fully understanding the complexities of the human gaze in videos. In this paper, we present a multi-task, multimodal model based on Contrastive Language–Image Pre-training (CLIP), designed to jointly predict atomic-level and event-level gaze communication, along with gaze target estimation. Specifically, we leverage the Vision-Language model to capture and utilise the semantic information between the atomic-level and event-level gaze communication categories. Additionally, most datasets in this field lack comprehensive annotations for both levels of gaze communication and detailed gaze target information. Therefore, we present a fully annotated gaze communication dataset, GP-Static++. We validate our model on GP-Static++ and several publicly available datasets, demonstrating its state-of-the-art performance.

If you find our work is useful, please consider giving a star and citation. And our dataset GP-Static++ is an extension of GP-Static made by Fei Chang, Jiabei Zeng, Qiaoyun Liu, and Shiguang Shan in "Gaze pattern recognition in dyadic communication", we are really thankful for their work, so if you use our dataset, please also cite their work.
@inproceedings{peng2025multitask,
title={Multi-Task Gaze Communication Understanding},
author={Cheng Peng and Oya Celiktutan},
booktitle={Proceedings of the 33rd ACM International Conference on Multimedia},
year={2025},
address={Dublin, Ireland},
publisher={ACM},
doi={10.1145/3746027.3754724}
}@inproceedings{chang2023gaze,
title={Gaze pattern recognition in dyadic communication},
author={Chang, Fei and Zeng, Jiabei and Liu, Qiaoyun and Shan, Shiguang},
booktitle={Proceedings of the 2023 Symposium on Eye Tracking Research and Applications},
pages={1--7},
year={2023}
}